In late January, I joined Khan Academy as the third member of the infrastructure team. We were just starting a big performance push, so I spent my first week or two improving our profiling tools and finding and fixing some easy slow spots (including speeding up the home page by over a second). However, every time I profiled any page, I found that the A/B testing framework, GAE/Bingo, was always one of the slowest pieces. I had some ideas on how to make some incremental improvements to speed it up, but instead, I was given a much more ambitious project: to rethink and rewrite the whole A/B testing system from scratch. I had plenty of sources of guidance and advice, but I, the new guy, was to be the sole owner and author of the new system. I was up for the task, but it was nevertheless a bit daunting.
Instead of the old strategy of keeping the A/B test data continuously up-to-date using memcache (and periodically flushing to the App Engine datastore), the new system would report events by simply logging them, and those log statements would eventually make their way into Google BigQuery through an hourly MapReduce job based on log2bq. From there, the real A/B test processing would be done completely in SQL using BigQuery queries. Since we were revamping GAE/Bingo using BigQuery, there was an obvious name: BigBingo.
Of course, that three-sentence description leaves out pretty much all of the details and makes some dangerous assumptions, but the high-level plan ended up working (with some tweaks), and I’m happy to say that all A/B tests at Khan Academy are now running under BigBingo, and the last remnants of the old GAE/Bingo system are finally being removed. In this post, I’ll talk about why a rewrite was so important, how we think about A/B testing, and some specific points of the design and architecture of BigBingo. There are some additional cool details that are probably deserving of their own blog post, so look out for those in the future.
BigBingo is fast!
Most developers at Khan Academy had a sense that the old GAE/Bingo system was slow and BigBingo would improve overall performance, but I doubt anybody expected that the improvement would be as dramatic as it was. When I finally flipped the switch to turn off GAE/Bingo, the average latency across all requests went from a little over 300ms to a little under 200ms. The most important pages had even better results, but I’ll let the pictures do the talking:
The logged-in homepage got twice as fast:
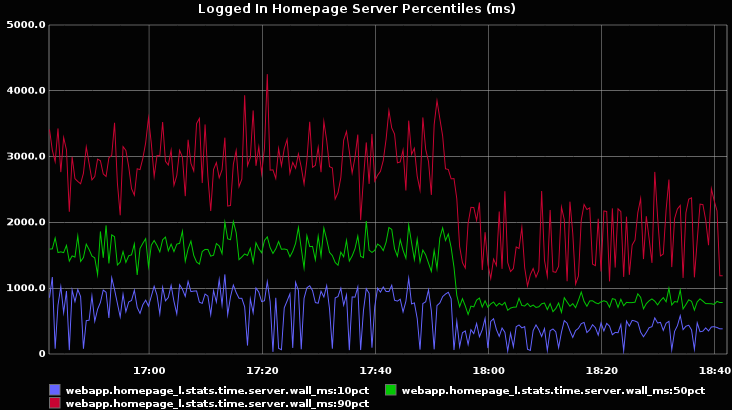
The logged-out homepage improved even more:
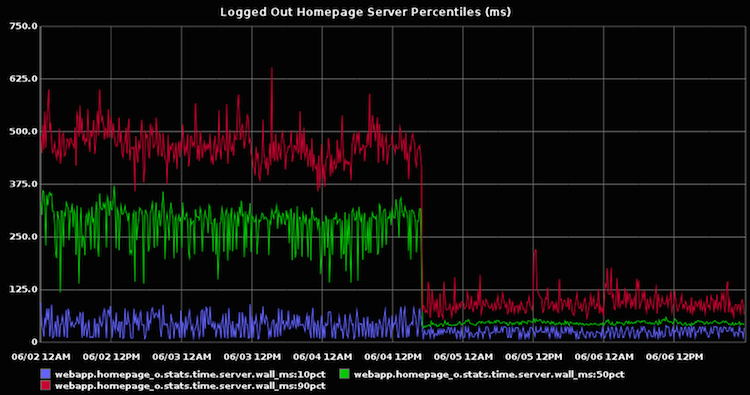
And our memcache went from “worryingly overloaded” to “doing great”:
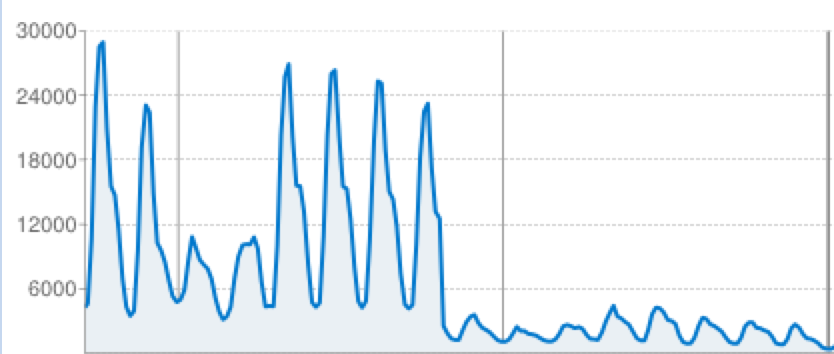
Of course, making the site faster makes users happier, but it has another big benefit: cost savings. If requests can be processed twice as fast, we only need half as many App Engine instances running at a given time, so our App Engine bill drops significantly. Since Khan Academy is a nonprofit running off of donations, it’s important to us to have an efficient infrastructure so we can focus our money on improving education, not upkeep.
A/B testing at Khan Academy
A/B testing isn’t just some occasional tool at Khan Academy; it’s an important part of our engineering culture, and almost any change that we care about goes through an A/B test first, often multiple A/B tests. Right now, there are 57 A/B tests actively running, which is an average of about two active A/B tests per developer.
Unlike “traditional” A/B testing (which tends to maximize simple metrics like ad clicks, purchases, etc.), Khan Academy’s A/B testing tries to maximize student learning. That means that we try out much more advanced changes than just little UI tweaks, and measuring success is a huge challenge by itself. Here are some examples of A/B tests we do:
- We have a sophisticated system that tries to understand a student’s knowledge level and recommend the best exercises for them, and we’re always making little improvements to it. For example, we recently tried out a new system to detect when users are below their learning edge and advance them through the material more quickly. Learners under the new system progressed further, as expected, and they almost always stayed at their advanced level rather than being demoted, so we rolled out the new algorithm to all users.
- We’ve been experimenting with providing message snippets to teach our users that learning makes them not just more knowledgeable, but smarter as well. This specific motivational approach turns out to be surprisingly effective, and results in increased site usage and learning outcomes, so we’re trying out various different approaches to deliver the message in the most effective way.
- We recently switched the homepage background to one we liked better. It didn’t improve any metrics noticeably, but the A/B test verified that it didn’t hurt anything either, so we kept the new background. We run lots of little experiments like this one.
What’s different about BigBingo?
In the years since GAE/Bingo was written, the devs at KA learned a thing or two about the right way to do A/B testing and what an A/B testing framework should really do, so BigBingo diverges from GAE/Bingo in a few important ways.
The data
Here’s what you’d see when looking at the latest results of an old GAE/Bingo experiment (I added a red box to indicate the “real” data; everything else is derived from those numbers):

For clear-cut results, a few numbers will do just fine, but what do you do when the results are unexpected or completely nonsensical? In GAE/Bingo, the best thing you could do was shrug and speculate about what happened. BigBingo is different: we keep around all raw results (user-specific conversion totals) as well as the source logs and the intermediate data used to determine those results. Since it’s all in BigQuery, investigating anomalies is just a matter of doing some digging using SQL.
Keeping the raw data also makes it easy to do more advanced analysis after-the-fact:
- Instead of just using the mean number of conversions, you can look at more interesting statistics like the median, percentiles, and standard deviation, and you can ignore outliers.
- You can cross-reference A/B test participation with more sophisticated metrics, like the learning gain metric that the data science team is working on.
- You can segment your analysis based on any property you can come up with. For example, you might want to focus on only new users or only long-term users.
Some other differences
- Instead of experiments needing to pick their metrics up-front, every experiment automatically tracks every conversion (currently we have about 200 of them).
- Since KA already has a culture of A/B testing, BigBingo encourages high-quality experiments rather than focusing on making experiments as easy as possible. Every experiment has an owner assigned and a description explaining what the experiment is for and the experimental hypothesis. When an A/B test is stopped, the author is forced to fill in a conclusion. Whenever an experiment starts or finishes, a notification is sent to the entire team, so it’s easy to see what kinds of ideas everyone else is trying out and how they are going.
- BigBingo doesn’t try to be real-time, which makes the implementation much simpler. After all, up-to-the-minute A/B test results are pretty useless anyway.
- The use of memcache counters added a little bit of complexity to GAE/Bingo, which I was happy to get rid of. Not only were there complex details, running BigBingo and GAE/Bingo side-by-side revealed some additional race conditions in GAE/Bingo that weren’t known yet.
Implementation
Here’s a big-picture overview of what BigBingo looks like:
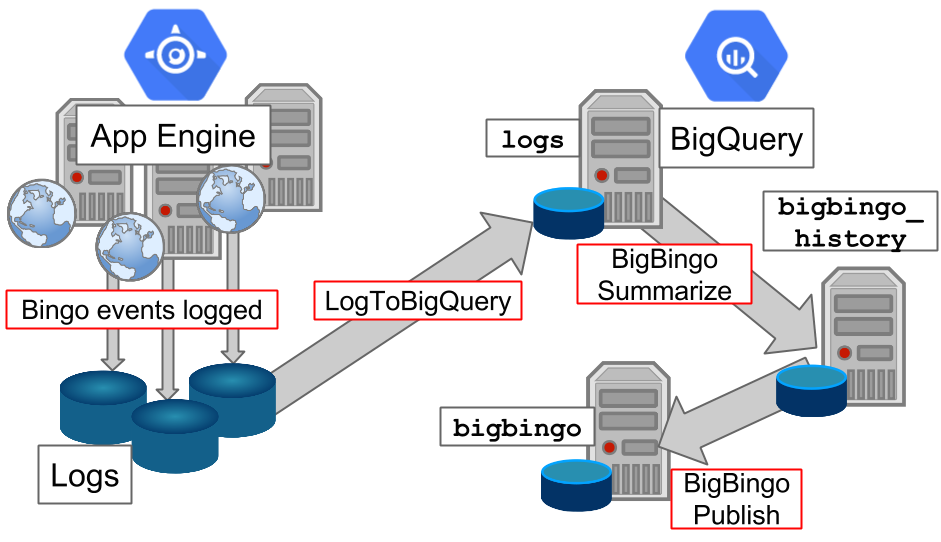
Here’s how the data flows from a user-facing request to BigQuery, then to the dashboard UI:
- When a user enters into an A/B test, that event is recorded through a log
statement. The user’s alternative is chosen through a deterministic function
similar to
hash(experiment_name + user_id) % num_alternatives, so no RPCs are necessary to coordinate that information. - When a user triggers a conversion event, it is recorded through a log statement.
- In the hourly LogToBigQuery log export process, the raw log events (called “bingo events”) are parsed and extracted into custom BigQuery columns to be included in the normal request logs tables.
- Every two hours, the BigBingo Summarize task runs and processes the new logs
to compute the latest A/B test numbers, following a few rules:
- If a user participates multiple times in an A/B test (which is common), only the earliest event counts.
- A conversion event only counts for an experiment if the event happened after the user first participated in the experiment.
- For each conversion, BigBingo computes both the total number of times the conversion was triggered and the total number of distinct users that triggered the conversion.
- The latest data is cleaned up and copied to a “publish” dataset where it can be conveniently accessed.
- The BigBingo dashboard, a web UI, queries these results to disply all data about a given experiment: the historical participant and conversion numbers, as well as p-values for each alternative.
Most of the details are reasonably straightforward, but I’ll dig into what’s probably the most controversial aspect of this architecture: the decision to use Google BigQuery for all storage and processing.
About BigQuery
If you’re not familiar with BigQuery, it’s a hosted Google service (really an externalization of an internal Google service called Dremel) that allows you to import giant datasets and run nearly-arbitrary SQL queries on them. BigQuery is way faster than MapReduce-based SQL engines like Hive: you’re borrowing thousands of machines from Google for just the duration of your query, and all work is done in-memory, so queries tend to finish in just a few seconds. The primary use case for BigQuery is for human users to manually dig into data, but I’ll show how it can also be used to build stateful data pipelines.
BigQuery supports nearly all SQL, but don’t let that fool you into thinking it’s anything close to a relational database! It has a small set of primitives that’s different from anything I’ve worked with before:
| Operation | Price |
|---|---|
| Import CSV/JSON data into a table | Free |
| Run a SELECT query | 0.5 cents per GB in all columns touched |
| Store a query result as a new table | Free |
| Apppend query results to the end of a table | Free |
| Copy a table | Free |
There are a few more operations that are less common, but the ones I listed are the most common ones.
Notice anything missing? No transactions? Not even a way to update or delete rows? No way to pull out a single row without paying for the whole table? How can you possibly keep track of A/B test results in such a restricted system? You’re pretty much stuck with the following rule:
To update a table, you must completely rebuild it from scratch with the new values.
That’s crazy, right?
It certainly feels like an architectural sin to rebuild all of your data over and over, but it’s not as unreasonable as you might think. BigQuery is quite cost-efficient (some rough numbers suggest that it’s more than 10x as cost-efficient as MapReduce running on App Engine), and there are lots of little tricks you can do to reduce the size of your tables. By designing the table schemas with space-efficiency in mind, I was able to reduce BigBingo’s data usage from 1TB ($5 per query) to 50GB (25 cents per query). (I’ll go over the details in a future blog post.)
There are also some huge usability advantages to using BigQuery over another batch processing system like MapReduce:
- When I was designing the queries and schema, I could try things out on real production data from within the BigQuery web UI and get results back in seconds. This meant that I could work through almost all architectural details before having to write a line of Python code.
- Once I did start to write code, I could run the full job completely from my laptop, with no need to push code out to servers in order to iterate. Whenever a query had a problem, it showed up in the “Query History” section of the BigQuery web UI, and I could easily debug it there.
- Sanity-checking the intermediate steps and hunting down problems in the data was easy because everything was immediately accessible through SQL.
Taking advantage of immutable storage
At first, having to deal with only immutable tables felt like an annoying restriction that I just had to live with, but as soon as I started thinking about making the system robust, immutability was a huge benefit. When thinking through the details, I discovered some important lessons:
- Never append to the end of a table. Keep tables immutable and queries idempotent.
- A table’s name should exactly define its contents.
This is probably best explained by looking at a simple data pipeline similar to BigBingo. First, I’ll give a straightforward but fragile approach, then show how it can be improved to take advantage of BigQuery’s architecture.
Goal: Keep track of the median number of problems solved, problems attempted, and hints taken across all users.
Every hour, the following queries are done to update the latest_medians
table:
Step 1: Extract the events from the logs table into a table called
new_event_totals:
1 2 3 4 5 6 7 8 9 10 | |
Step 2: Combine new_event_totals with the previous full_event_totals
table to make the new full_event_totals table:
1 2 3 4 5 6 7 8 9 | |
Step 3: Find the median of each metric, and write the result to a table
called latest_medians:
1 2 3 4 5 6 | |
This code ends up working, but it doesn’t handle failure very well:
- Step 2 isn’t idempotent. For certain errors (e.g. a connection timeout when submitting the query), there’s no way to know for sure if it’s safe to retry, or if it succeeded in the first place.
- If the job fails between steps 2 and 3, it can’t be safely retried, so you need to either manually re-run step 3 or live with out-of-date results for an hour.
- If the job fails before step 2 finishes and isn’t retried before the next job runs, the event_totals table will lose all events from that hour.
- If the logs weren’t successfully loaded into BigQuery, Step 1 will think that nothing happend in that hour and will silently compute the wrong results.
To solve all of these problems, just include a timestamp in each table’s name. The background job then takes as a parameter the particular hour to process, rather than trying to figure out what the “latest” hour is. Here’s what it would do if you run it with the hour from 6:00 to 7:00 on July 1:
Step 1: Read from logs_2014_07_01_06 (the logs for 6:00 to 7:00 on July
1) and write to the table new_event_totals_logs_2014_07_01_06 (the new events
for 6:00 to 7:00 on July 1).
Step 2: Read from new_event_totals_logs_2014_07_01_06
and full_event_totals_2014_07_01_06 and write to the table
full_event_totals_2014_07_01_07 (the full totals as of 7:00 on July 1).
Step 3: Read from full_event_totals_2014_07_01_07 and write to the table
latest_medians_2014_07_01_07 (the medians as of 7:00 on July 1).
The job takes the hour to process as a parameter, and reads the previous hour’s tables to generate that hour’s tables. Making three new tables per hour may seem wasteful, but it’s actually just as easy and cheap as the previous scheme. The main problem is that the tables will just accumulate over time, so you’ll rack up storage costs. Fortunately, BigQuery makes it easy to give an expiration time to tables, so you can set them to be automatically deleted after a week (or however long you want to keep them).
The core BigBingo job has 7 queries/tables instead of 3, but it is designed with the same strategy of keeping all old tables, and this strategy has helped tremendously and kept BigBingo’s data consistent in the face of all sorts of errors:
- Various transient errors (connection timeouts, internal BigQuery errors, etc.) have caused the whole BigBingo job to occasionally fail, and in these cases, it’s always safe to just retry the job.
- The log import process has sometimes failed and sometimes taken too long to run, and in both situations, BigBingo automatically fails (and sends an email reporting the failure) because the data it depends on isn’t ready yet.
- Whenever BigBingo fails, all future BigBingo jobs fail (rather than computing incorrect data) until the data is caught up.
- Sometimes two instances of the job end up running at the same time. Since the intermediate data is all timestamped, this doesn’t cause any problems.
- One time, when retrying a failed job, I accidentally gave an incorrect UNIX timestamp. The wrong hour was processed, but it didn’t hurt data integrity at all.
- In one or two cases, bugs have made the data actually incorrect for a while. Repairing the system is easy: just fix the bug and re-run the BigBingo job from before the bug was introduced.
The system is completely foolproof: I could replace cron with a thousand monkeys repeatedly triggering BigBingo jobs with random UNIX timestamps, and the system would still eventually make progress and remain completely consistent (although it would be a little less cost-efficient). That level of safety means I can stop worrying about maintenance and focus on more important things.
Where’s the source code?
Ideally, BigBingo would be a self-contained open-source library, but it currently has enough dependencies on internal KA infrastructure that it’s both hard to make general and would be a bit difficult to use in isolation anyway.
That said, there’s no reason I can’t share the code, so here’s a Gist with pretty much all of the code (at the time of this blog post). I put an MIT license on it, so feel free to base work off of it or use any of the self-contained pieces.
Khan Academy has lots of open-source projects, and it’s not out of the question for BigBingo to be made truly open source in the future, so let me know in the comments if you think you would use it.
That’s all for now
Curious about any more details? Think we’re doing A/B testing all wrong? Let me know in the comments!